클러스터
클러스터는 엘라스틱서치의 가장 큰 단위이며, 하나의 클러스터는 여러개의 노드로 이루어져있다.
서로 다른 클러스터는 데이터의 접근이나 교환을 할 수 없는 독립적인 시스템으로 유지된다.
여러 대의 서버가 하나의 클러스터를 구성할 수도 있으며, 그 반대도 하나의 서버에 여러개의 클러스터가 존재할 수도 있다.
같은 클러스터 이름으로 노드를 실행하는 것만으로 자동 확장된다! (따로 설정 해줄 필요가 없다!)
노드
노드는 마스터 노드와 데이터 노드로 구분된다.
마스터 노드는 전체 클러스터 상태의 메타 정보를 관리하며, 기존 마스터 노드가 종료되면 새로운 마스터 노드가 선출된다.
데이터 노드는 실제 데이터가 저장되는 노드이며, 하나밖에 없는 경우 복사본은 생성되지 않는다.
마스터노드와 데이터노드가 반드시 상호 배타적 관계는 아니다
일반적으로 데이터 노드는 외부 접근을 차단한다.
노드는 각각 하나의 엘라스틱서치 프로세스로써 실행된다.
별도의 설정을 하지 않고 엘라스틱서치를 실행하면 임의의 노드가 하나 생성된다.
같은 시스템, 또는 네트워크 바인딩이 되도록 설정한 다른 시스템에서 같은 클러스터명으로 설정된 ES를 실행하면,
또 다시 임의의 이름의 노드가 실행되면서 두 개의 노드는 하나의 클러스터로 바인딩 되어 묶인다.
# mkdir -p /svc/rtfd/
# wget
http://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-0.20.4.tar.gz
$ tar xvzf elasticsearch-0.20.4.tar.gz
$ cd ~
$ ln -s /svc/rtfd/elasticsearch-0.20.4 elasticsearch
$ bin/plugin -install mobz/elasticsearch-head
$ bin/plugin -install lukas-vlcek/bigdesk
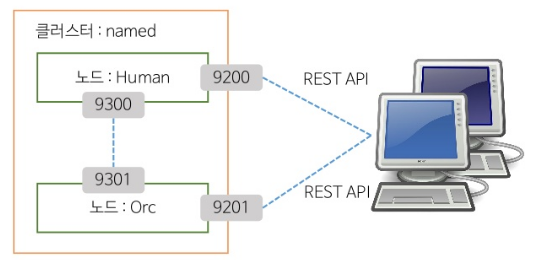
노드바인딩
같은 클러스터 이름을 가지고 실행된 노드는 자동으로 바인딩된다.
9200번부터 REST API를 위한 HTTP 통신 포트가 할당된다.
9300번부터 노드간 바인딩을 위한 포트로 할당된다.
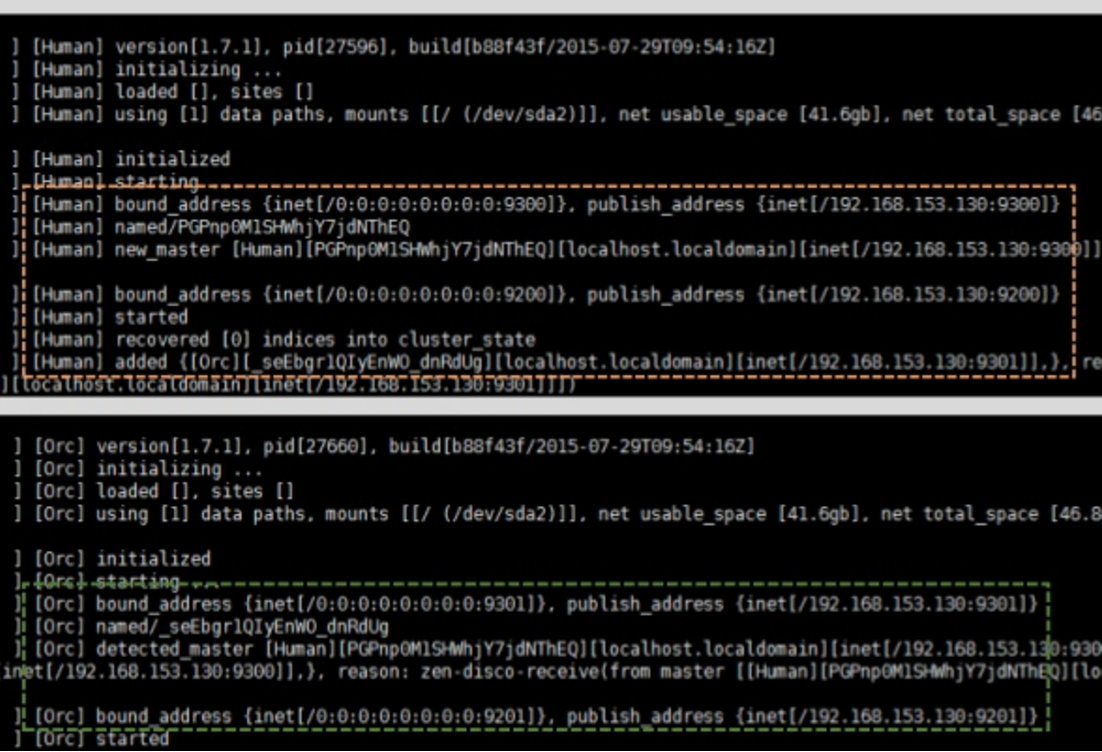
두 개의 노드가 바인딩 되면, 아래와 같은 로그가 뜬다
네트워크 바인딩
효율적인 스케일 아웃을 위해 네트워크에 있는 다른 서버의 노드와도 바인딩이 가능하다
네트워크 바인딩을 위해 젠 디스커버리(ZEN DISCOVERY) 기능을 내장하고 있다
멀티캐스트와 유니캐스트의 사용을 권장한다 (공식적으로는 유니캐스트 사용을 권장한다)
반드시 두 엘라스틱 서치의 버전은 동일해야 한다!
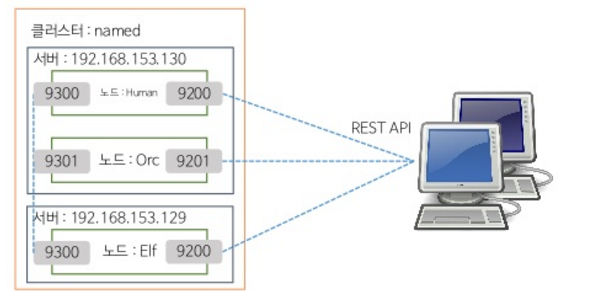
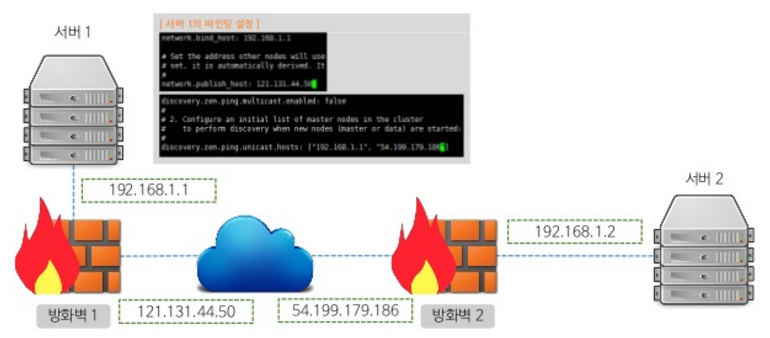
방화벽 외부 서버 사이의 네트워크 바인딩
샤드와 복사본
샤드는 데이터 검색을 위해 구분되는 최소 단위이며, 아파치 루씬에서 사용되는 매커니즘이다.
Indexing된 데이터는 여러 개의 샤드로 분할되어 저장되는데, 기본적으로 Index당 5개의 Shard와 2개의 Replication으로 분리된다.
샤드와 복사본 개수를 설정할 때말고는 사용자가 직접 샤드에 접근하는 경우는 없다.
사용자는 인덱스 단위로 데이터를 처리하고, 샤드는 엘라스틱서치가 직접 노드로 분산시키는 작업을 한다.
데이터가 Indexing되어 저장되는 공간을 Primary Shard(최초샤드)라고한다.
최초의 데이터가 Indexing되면 동일한 수만큼 Replication(복사본)을 생성하는데, Replication을 사용하는 이유는 크게 두 가지다.
- Fail Over(데이터 손실)을 방지하여, Primary Shard가 유실되는 경우 복사본을 최초 샤드로 승격한다
- 성능 향상을 목적으로, Primary Shard와 복사본을 동시에 검색해서 더 빠르게 데이터를 찾을 수 있다.
기본적으로 Primary Shard와 Replication는 서로 다른 노드에 저장되며, 실행 중인 노드가 하나일 경우 복사본은 생성되지 않는다.
- 또한, 이미 생성된 Index의 샤드 설정은 변경 불가능하다.
ES 구동 후 정보 확인
$ curl -XGET http://localhost:9200