검색(URI vs Request Body)
URI
- GET 방식을 사용해 URI를 통해 인자 전달
- p128-145
RequestBody
- POST 방식을 사용해 JSON으로 인자전달
- p146-162
검색해보자
예제 5.2 books 인덱스, book 타입에서 hamlet 검색
http://192.168.99.100:9200/books/book/_search?q=hamlet
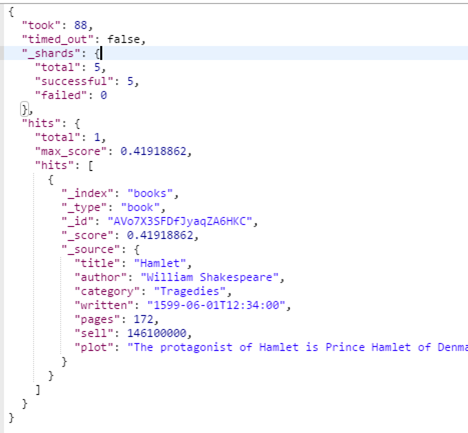
hamlet이란 단어가 어떤 필드에 있던 찾아와! → 1개 찾음(홋!)
여기서 ES의 특징 중 하나인, 멀티태넌시를 적용할 수 있다!! (전체 대상)
http://192.168.99.100:9200/books,magazines/_search?q=time
클러스터의 모든 인덱스에서 검색하기 위해 _all을 사용할수도 있다!
http://192.168.99.100:9200/_all/_search?q=time
p 128~13?
상세검색/통합검색
URI를 사용했을때의 문제
- URI는 빈칸이 허용 안됨
- 이스캐이프처리: ‘ ‘ → ‘+’, ‘+’ → ‘%2B’, ‘%’ → ‘%25’
- 길이 제한이 있음 (4000자?)
예제 5.7 전체 인덱스의 title 필드에서 time 검색
http://192.168.99.100:9200/_search?q=title:time AND machine
- ‘ ‘은 %20으로
- AND는 대문자만 허용
Full-Text Search
- RDB의 like 문법과 같음
- like를 개선한 버전이 full-text search
DB는 요 아래 3개가 끝이다.
- Full-text search
- Stopword vs ngram 방식
‘sampleTest’
‘TestSample’
‘1sample2’
- select * from student where name like ‘%sample%’
- 엄청난 부하가 있음
- OR로 연결되어 있기 때문에
- Full-Text Search
- 중급 수준 ><
- 결과는 같은데 구현 방식이 다르고, 서버도 훨씬 부담이 적어
- 검색 엔진과 같은 방식이다
- 스키마를 고려하지 않겠다(스키마를 고려해서 느리거든..)
- 다 글로 인식하겠어! 닥치는 대로 찾겠다! (원시적인게 젤 빠른거야~)
- String matching 방식으로 가자. 단순한 반면, 무시막지하게 하지
- 이 방식도 두가지로 나뉘어 진다.
- 토크나이저
- standard 토크나이저
- whitespace 토크나이저(space, tab,enter)
- stopword랑 거의 비슷한데 조금 다름
- stopword는 단어로 쪼개는 것
- ‘나는 집에 간다’에서 집으로 검색하면 안나옴
- Ngram 토크나이저
p327
은 물리적으로 쪼갠거….
- alpa-numeric???
다시 올라와서...
검색
(p130
)
예제 5.9 df 매개변수를 사용해서 title 필드에서 time 검색
http://192.168.99.100:9200/_search?q=time&df=title
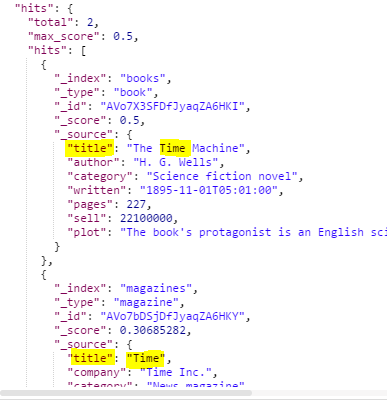
예제 5.10 default_opreator 매개변수를 사용해서 기본 조건 명령어를 AND로 지정
http://192.168.99.100:9200/_search?q=time+machine&default_operator=AND

예제 5.11 explain 매개변수를 사용해서 검색 처리 결과 표시
http://192.168.99.100:9200/_search?q=title:time&explain


예제 5.12 _source 매개변수를 false로 설정해 도큐먼트 내용을 배제하고 검색
GET http://192.168.99.100:9200/_search?q=title:time&_source=false

예제 5.13 fields 매개변수를 사용해 title, author, category 필드만 출력
http://192.168.99.100:9200/_search?q=title:time&fields=title,author,category
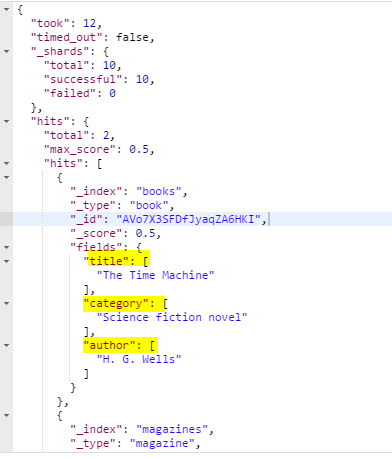
검색 결과 Sort
5.14 author 필드가 jules인 도큐먼트를 pages 필드를 기준으로 오름차순 정렬
http://192.168.99.100:9200/books/_search?q=author:jules&sort=pages
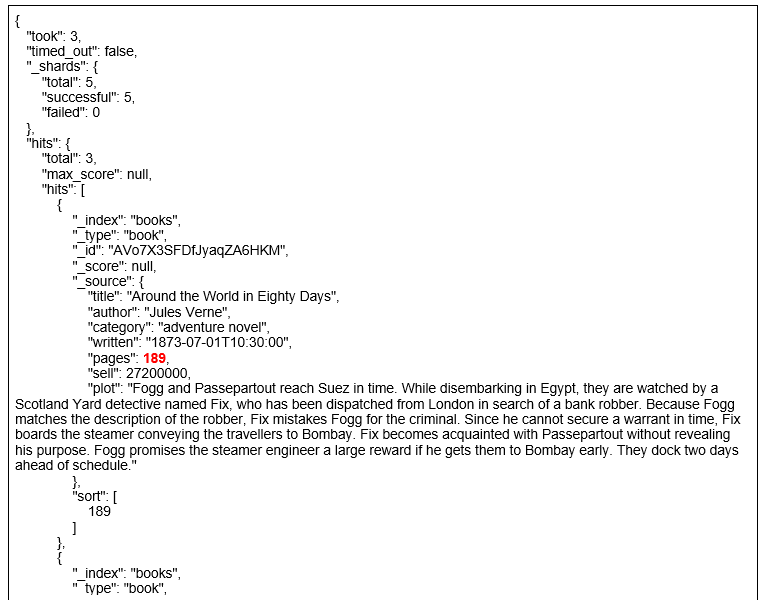

예제 5.15 author 필드가 jules인 도큐먼트를 pages 필드를 기준으로 내림차순 정렬
http://192.168.99.100:9200/books/_search?q=author:jules&sort=pages:desc
예제 5.16 author 필드가 jules인 도큐먼트를 title 필드를 기준으로 오름차순 정렬
- 문장 중에서 제일 중요하다고 판단되는 키워드를 가지고 정렬을 한다 (덜덜)
- 첫단어로 정렬하고 싶으면 title 필드에 not_analyzed로 매핑을 설정해줘야 한다(뒤에 나옴)
http://192.168.99.100:9200/books/_search?q=author:jules&fields=title&sort=title

Timeout
- 매개변수로 검색이 수행되는 동안 기다리는 제한 시간
From
- 검색된 결과를 몇 번째 부터 출력할까?
- 예제 5.18 from매개변수를 사용해서 3번째 결과부터 표시
- http://192.168.99.100:9200/books/_search?q=author:jules&fields=title&from=2
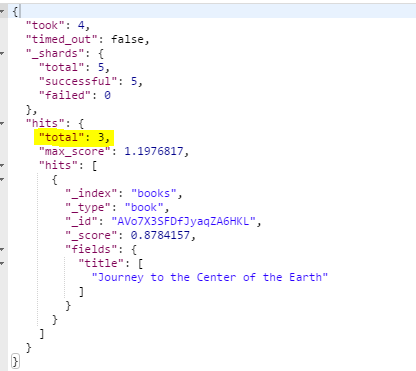
실제 검색 결과는 3건이지만, 3번째 결과부터 표시되므로 1건만 표시됨
5.2.10 Size
- 검색된 결과 도큐먼트를 몇개까지 표시할지 지정한다.
- 지정하지 않으면 기본 값은 10개이다.
- 예) 검색결과 정확도 상위 5개 출력해라 등등
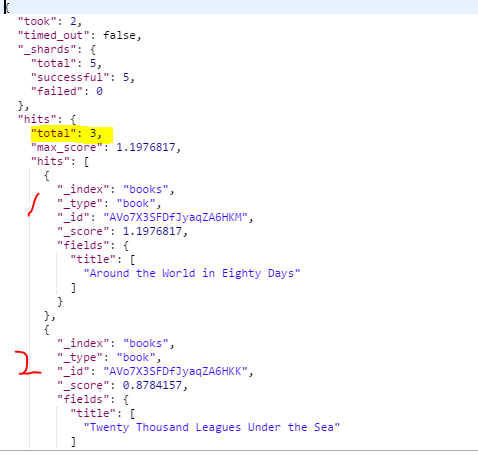
- http://192.168.99.100:9200/books/_search?q=author:jules&fields=title&size=2
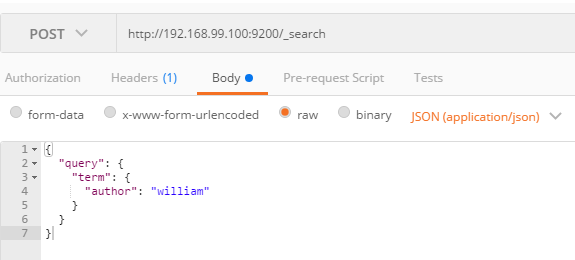
예제 5.23 Request Body로 author 값이 william인 값 검색
HTTP에 대해서
web webdav(80) 기본적으로는 POST/GET만 제공한다. --> 가져올 때는 GET, 변경할 때는 POST를 쓰라고 만들어놨는데, 개발자들이 자꾸 GET만 쓰더라! POST/GET/PUT/DELETE (일반 웹에는 이런게 없다.) Telnet → ssh 23/22
FTP → scp, ftps/sftp 21/22
방화벽
80
예제 5.24 from1, size2, filelds[title,category] 조건으로 전체 필드에서 time 검색
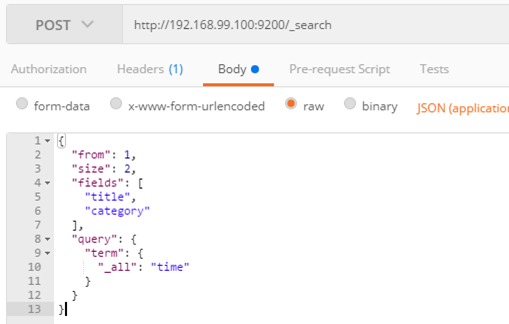
p149 Sort
예제 category - 내림차순, pages, title-오름차순 순서로 검색 결과 정렬
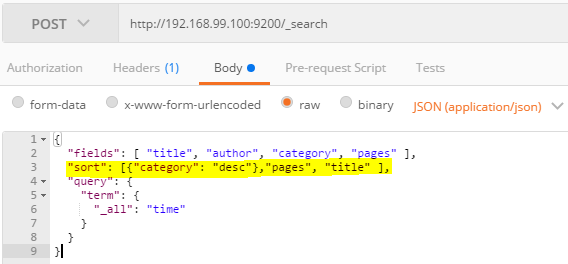

결과는 6개지만 size: 2 하여 2개만 나온다
JSON은 javacript에는 내장되어 있고
Java는 JSON-simple 을 깔아서 써야한다.
p157
partial_fields, fielddata_fileds
와일드 카드를 지정해서 검색할 수 있다.
p160 Highlight
기본 <em></em>으로 표기되는데, 바꿀수 있다.