Document 생성/조회
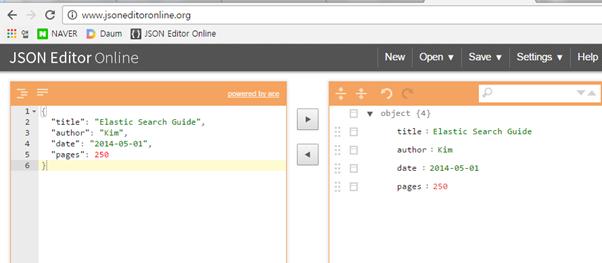
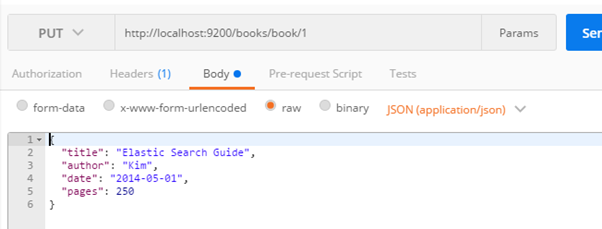
여기까진 DB랑 비슷하다. 딱히 검색이라고 할 순 없지!
데이터 삭제
(교재 p73 )
/books/book/1 도큐먼트를 삭제한다.
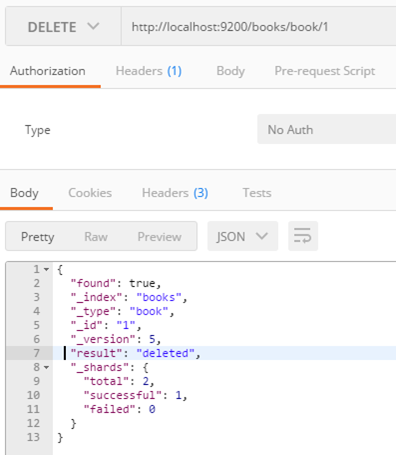
삭제한 도큐먼트를 조회하면 결과에 result: false라고 표시되고, 도큐먼트를 찾을 수 없다.

하지만 도큐먼트를 삭제하더라고 도큐먼트의 메타 정보는 여전히 남아 있다.
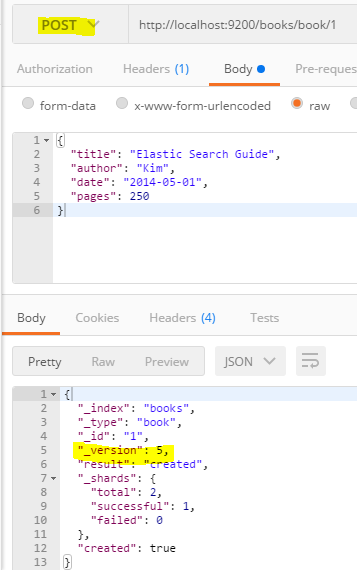
따라서 도큐먼트의 삭제는 , 실제로 삭제되는 것이 아니라 도큐먼트의 _source에 입력된 데이터 값이 빈 값으로 업데이트되고 검색되지 않게 상태가 변경되는 것으로 이해하는 것이 편하다.
DELETE를 타입단위에서 삭제한다.
-- PASS
인덱스를 삭제
삭제하고 나서 조회하면

404에러가 뜬다.
p75~81
데이터 업데이트 API
도큐먼트 데이터의 업데이트는 _update API의 두개의 매개변수인 doc와 script를 이용해서 데이터를 제어할 수 있다.
- doc 매개 변수는 도큐먼트에 새로운 필드에 추가(append)하거나 기존 필드 값을 변경(update)하는데 사용한다.
- script 매개변수는 좀 더 복잡한 프로그래밍 기법을 사용해서 입력된 내용에 따라 필드의 값을 변경하는 등의 처리에 사용한다. (뒷부분에 언급)

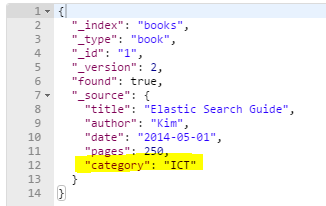
이 도큐먼트에 category 필드를 추가하자 (ICT값으로)

get하면 추가된걸 확인할 수 있다
Author를 “Lee”로 변경해보자
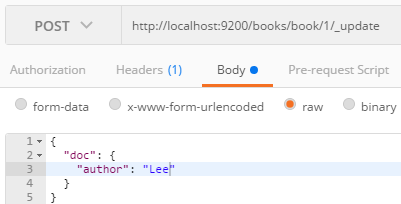
GET해보면
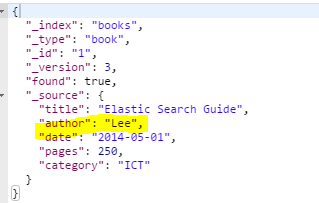
따랑~ 성공이다
p82-91
파일 벌크 입력
+) 참고내용입니다
DBMS는 CRUD 용도로 사용하지만 CRUD를 모두 잘할 수는 없다.
대부분 CUD (vs) R 이다. 그리고 DBMS는 Retrive가 CUD에 비해 압도적으로 많다고 생각한다( R>>CUD)
따라서 빠른 검색에 포커싱이 맞춰져있다.
이게 안맞는 경우도 있다. 데이터의 수정 삭제가 검색보다 많은 경우가 있다.
(예: Logging하는 경우... SKT 데이터 사용하면 logging해서 빌링 함)
(예: Twitter, 글한번쓰면 팔로워 10만명에게 write되어야 함)
그래서 이게 안맞는 거다. 그래서 write에 특화된 게 NoSQL 인가…
bulk란 대량의 데이터를 한번에 집어넣는다는 의미이다.